Just today, I issued a Pull Request for a new feature in GNU Radio. This adds a new form of what we already called the QT GUI Entry widget. That widget provides a simple QLineEdit box where we type in values, they get stored as a Python variable, and we pass these variables around like normal GRC variables. When running, updates to the entry box are propagated to anything using that variable in the flowgraph.
We're trying to move beyond this world where everything is in a Python file that's assumed to be completely local. Instead, we want to move to a world where we can use the message passing architecture to manage data and settings. So when we have a message interface to a block, we might want to post data or update a value through that message interface from a UI somehow. This leads us to the possibility that the UI is a separate window, application, or even machine from the running flowgraph. We have already made strides in this direction by adding the postMessage interface to ControlPort, which I spoke about in the last post on New Way of Using ContorlPort. However, ControlPort can take some time to set up the application, craft the UI, and make a working product. Aside from that method, we wanted to have easy ways within GRC to build applications that allow us to pass and manage messages easily. Hence the new QTGUI Message Edit Box (qtgui_edit_box_msg).
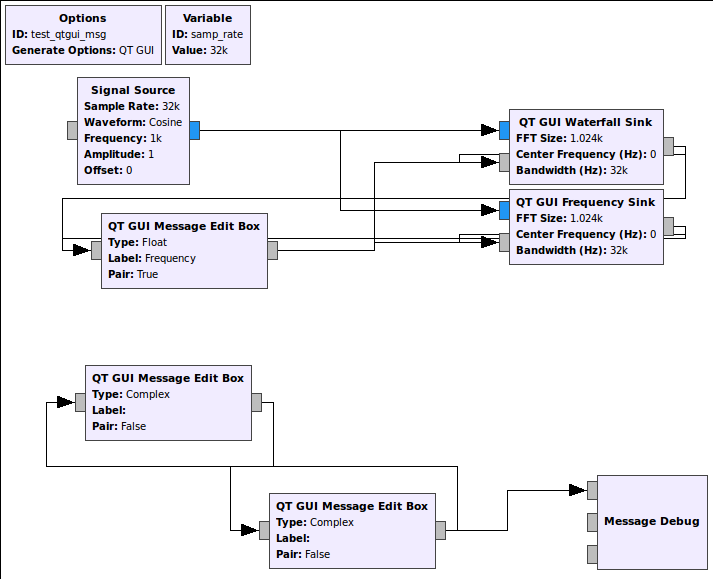
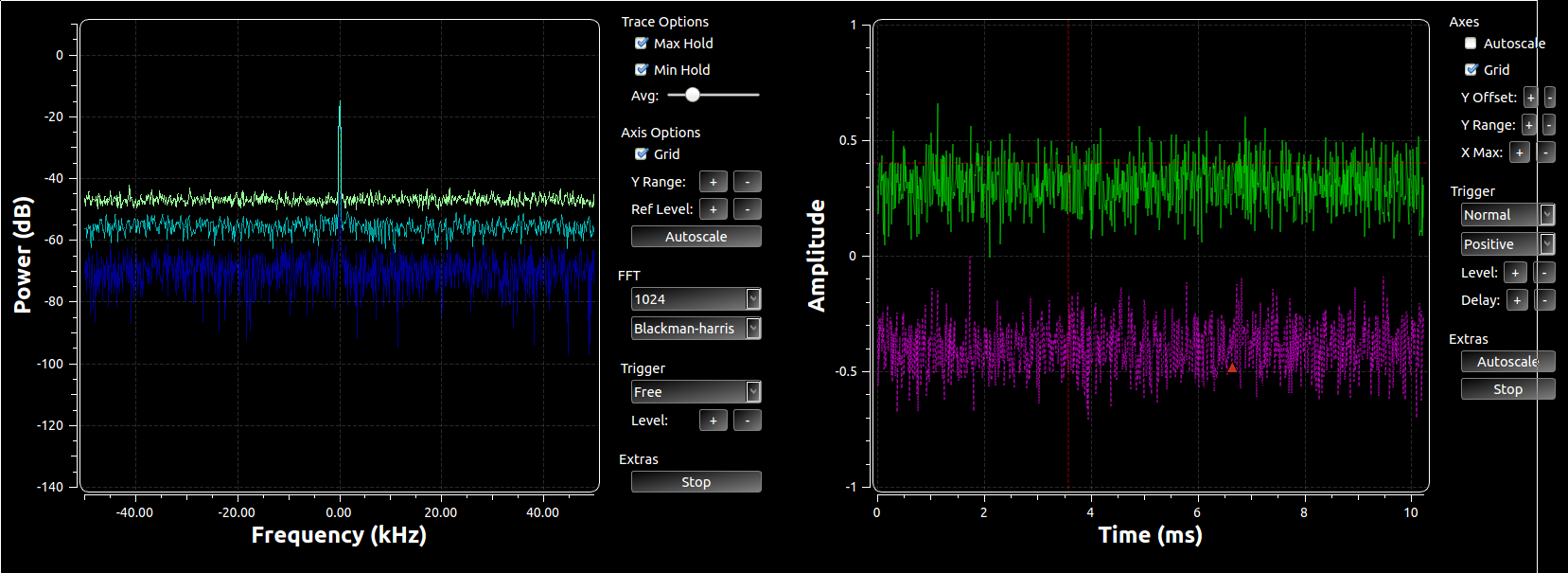
This is an flowgraph example that now comes with GNU Radio's gr-qtgui (test_qtgui_msg.grc). This shows the use of three of the new message edit boxes. In the upper part of the graph, we have the edit box controlling the center frequency of a Waterfall and Frequency Sink. These sinks can take in a message that's a PMT pair in the form ( "freq" <float frequency> ). So the edit box has a setting called Pair that sets this up to handle the PMT pair messages. It's actually the default since we'll be using the key:value pair concept a lot to manage message control interfaces. When the edit box is updated and we press enter, it publishes a message and the two GUI sinks are subscribed to them, so they get the message, parse it, and update their center frequency values accordingly.
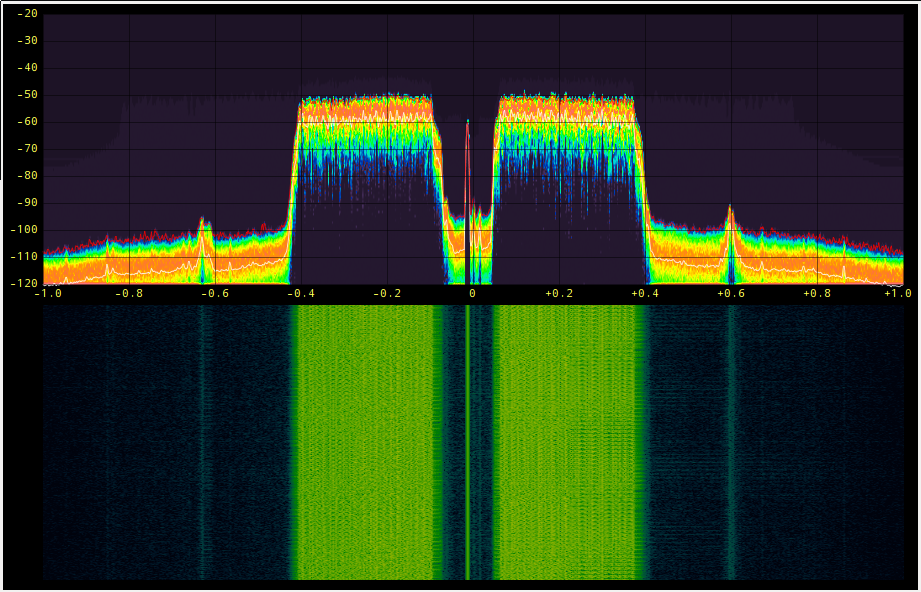
Now the flip side of this is that the edit boxes also have an input message port. This allows us to programmatically set the value inside the box. The two GUI sinks have the ability to have a user adjust their center frequency. When a user double-clicks on a frequency in the plot, the block sets that value as the center frequency and then publishes a message (in the same key:value pair where key="freq"). This means that not only is the widget we just double-clicked updated, anything listening for that message is updated. So the edit box is kept in sync with the change in the GUI. Now, when the new data received is different than what was in that edit box to begin with, the box re-emits that message. So now, say we double-clicked on the Frequency Sink near the 10 kHz frequency line. That message is propagated not only to the edit box, but the message also gets sent from that box through to the waterfall sink. Now all of the widgets are kept in sync. And because the re-posting of the message only happens when a change occurs, we prevent continuous loops. Here's the output after the double-clicking:

Both GUI display widgets have the same center frequency, and that value is also shown in the Frequency edit box above. Because it's using the pair concept, we have two boxes, the left for the key and right for the value.
This example has two other edit boxes that show up at the bottom of the GUI. This is to allow us to easily test other properties and data types. They are connected in a loop, so when one is changed, the other immediately follows. Note here that we are not using the pair concept but that the data type is complex. To make it easy on us, we use a Boost lexical_cast, which means we use the format "(a,b)" for the real and imaginary parts. All of this, by the way, is explained in the blocks'd documentation.
Now, we have the ability to pass messages over ZMQ interfaces. Which means we can create flowgraphs on one side of the ZMQ link that just handle GUI stuff. On the other side, we use ZMQ sources to pass messages around the remotely running flowgraph. Pretty cool and now very easy to do in GRC.
This is just one way of handling QT widgets as message passing blocks. Pretty easy and universal for sending messages with data we're used to. But it's just a start and a good template for other future widgets to have similar capabilities, like with range/sliders, check boxes, combo boxes, etc. All of these should be able to pretty easily use this as a template with different GUI widgets for manipulating the actual data.